

Für einen Artikel im Neon-Magazin hat der Journalist Tin Fischer gemeinsam mit dem Informatiker David Goldwich gezielt verschiedene Hashtags ausgewertet, unter denen auf der Fotoplattform Instagram Bilder hochgeladen wurden. Ein sehr interessantes Vorhaben, wie wir finden, das erstaunliche Ergebnisse ans Tageslicht brachte. In „Instagram-Leaks“ beschreibt der Autor, welche Daten die Nutzer von Instagram beim Hochladen und Teilen ihrer Fotos mit der Handy-App bedenkenlos preisegeben und wie einfach es ist, diese Informationen ganz legal auszuwerten. Wir haben mit dem Autor gesprochen.
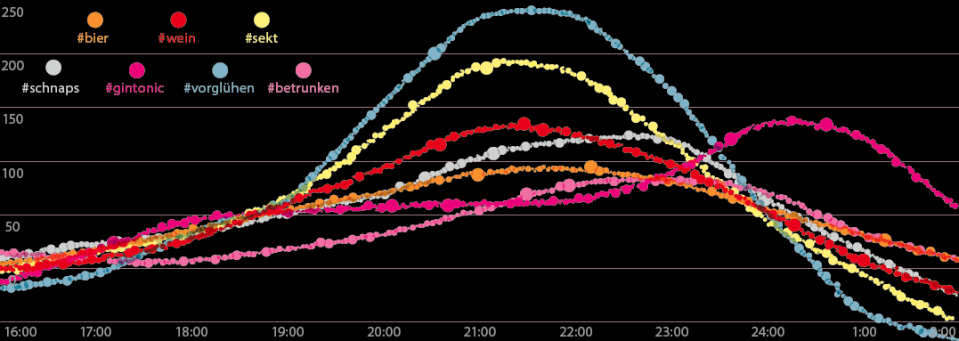
IM RAUSCH VERLIERT man die Kontrolle. Aber der Rausch folgt auch festen Regeln. Fotos, auf denen man #sekt trinkt, tauchen gegen 21 Uhr auf. #gintonic trinkt man erst nach Mitternacht. Das #vorglühen hat um 21 Uhr Konjunktur. Und richtig #betrunken sind die Leute um 24 Uhr. (Daten: 2013+2014) – Quelle: Instarama
Interview mit Tin Fischer
Ihr habt euch intensiv mit dem Nutzungsverhalten der User von Instagram auseinandergesetzt. Gab es Ergebnisse, die euch richtig umgehauen haben?
Tin Fischer: Mich zunächst mal, dass die Daten einfach so verfügbar sind. David als Informatiker fand das weniger überraschend. Und dann natürlich, dass sich noch niemand diese Daten genauer angeschaut hat. Instagram scheint wohl noch etwas unter dem Radar zu sein, obwohl es eines der größten sozialen Netzwerke der Welt ist.
Viele Menschen können mit dem Thema Daten wenig bis gar nichts anfangen. Warum habt ihr euch dennoch an diese Geschichte gewagt?
Als Journalist recherchiere ich ab und zu Infografiken für meine Artikel. Für eine Geschichte brauchte ich Tweets mit Geodaten, aber auf Twitter verwendet kaum jemand Geotags. Das ging also nicht. Doch dann sah ich zufällig die Seite iknowwhereyourcatlives.com. Da lokalisiert tatsächlich jemand Katzenbesitzer über ihre Katzenfotos. Ich dachte: ganz schön clever, denn aus irgendeinem Grund verwenden die Leute bei Fotos viel eher Geotags. Ich rief David an und fragte, ob man Instagram anzapfen könne. Er meinte, technisch sei das kinderleicht.
Wie lange habt ihr für die Programmierung und die Auswertung der Daten gebraucht, die ihr bei Instagram – ganz legal – abgezapft habt?
Es hat dann doch etwas länger gedauert als wir ursprünglich angenommen hatten. Wir begannen im vergangenen Sommer und die erste Version des Downloadprogramms stand schon nach ein paar Tagen. Aber dann hatte ich viele Sonderwünsche und wir mussten uns – neben unserer regulären Arbeit – erstmals überhaupt in das Thema Datenanalyse einarbeiten und den ganzen Kram wie Kartografie- und Linguistik-Programme lernen.
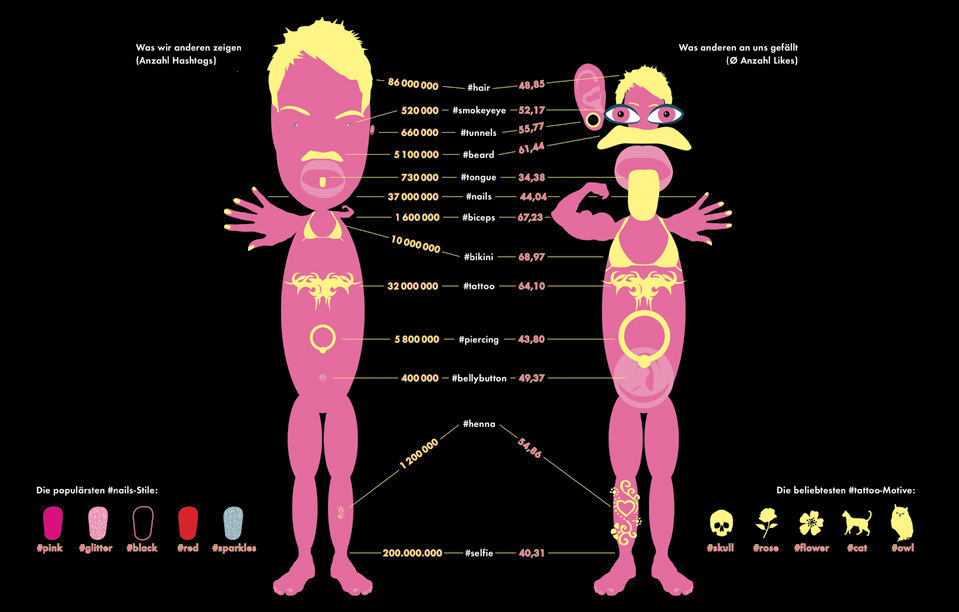
EINES DER BELIEBTESTEN MOTIVE der Instagrammer sind sie selbst – besser: ihr Körper. Es besteht allerdings ein großer Unterschied dazwischen, welche Körperpartien wir selbst mit einem Hashtag markieren (#hair) und welchen Anblick andere mit einem Like belohnen (#biceps). Die meisten Likes kriegen Bikinifotos. Nebenbei erfärt auf Instagram auch, welche Tattoomotive und Nagellacke in sind. (Daten: Januar 2015) – Quelle: Instarama
Wie haben die „Neon“-Leser auf euren Artikel reagiert?
Insgesamt, glaub ich, eher verblüfft und amüsiert. Wir haben ja bei dieser Arbeit vor allem nach Komik in den Daten gesucht und weniger nach sozialer Brisanz. Das hängt auch damit zusammen, dass die Daten von Instagram nicht all zu persönlich sind. Instagram ist eher ein Schaufenster, in dem man seine besten Seiten präsentiert. Für eine andere Geschichte hatten wir neulich all meine Google-Suchanfragen der letzten Jahre ausgewertet. Das geht dann schon eher ans Eingemachte.
Wie groß war denn das Datenvolumen, das ihr analysiert habt und vor allem, wie kommt man überhaupt an diese Daten ran?
An die Daten kommt man über die API ran, das ist sozusagen der Lieferanteneingang eines sozialen Netzwerks. Hier docken zum Beispiel auch Apps von Drittanbietern an. Man braucht dafür schon Programmierkenntnisse, aber diese API ist ein legaler offener Zugang. Das Datenvolumen ist schwer zu beziffern, weil man ja sehr viel runterlädt, das bei näherem Hinschauen dann doch langweilig ist.
Meinst du, dass eure Erkenntnisse auch auf andere soziale Netzwerke wie Facebook übertragbar sind?
Jedes soziale Netzwerk generiert andere Daten. Auf einer Fotoplattform wie Instagram geht es vor allem um Themen wie Reisen, Mode und Essen. Politik oder Technik spielen so gut wie keine Rolle. Auf Twitter ist es genau anders rum. Auch die Zielgruppen sind sehr unterschiedlich. Instagram ist eher jung und weiblich, deshalb kann man die Ergebnisse nur bedingt verallgemeinern.
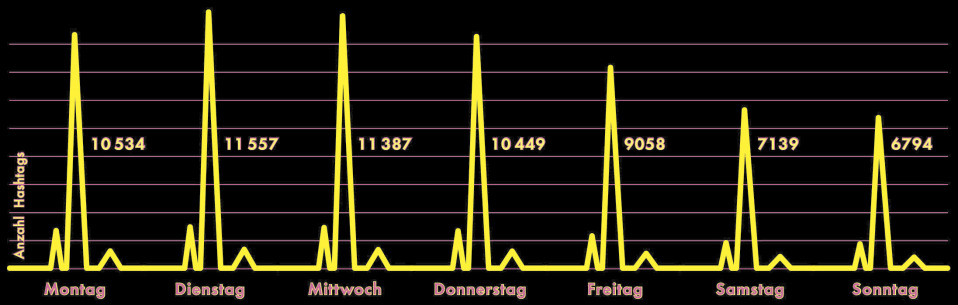
ES IST EIN MEDIZINISCHES RÄTSEL, aber am Wochenende liegen tatsächlich mit Abstand die wenigsten Instagram-Nutzer #krank im Bett. Funktioniert das Immunsystem besonders gut, wenn man eh schon frei hat? Die meisten Krankmeldungen gehen am Dienstag und Mittwoch bei den Arbeitgebern ein – aber das ist sicher nur der Stress. (Daten: 2013+204) – Quelle: Instarama
Welche persönlichen Konsequenzen ziehst du aus dieser Recherche?
Es ist schon ansteckend, sich Monate lang in dieser bunten, heilen Instagram-Welt zu bewegen. Man will irgendwann nur noch Sushi essen und Cro hören. Davon muss ich jetzt wieder runterkommen, wieder ernstere Musik hören.
Verhältst du dich nun anders im digitalen Raum, wo wir überall unsere Daten hinterlassen?
Ich bin da zwiegespalten. Also ich benutze heute die Suchmaschine DuckDuckGo, habe Cookies nur temporär aktiviert und logge mich stets aus Facebook aus, wenn ich im Web unterwegs bin. Aber klar, man büßt damit Komfort ein, die Produkte funktionieren nicht mehr gleich gut und die Online-Unternehmen werfen einem wohl irgendwann in die Kategorie querulanter Trottel. Mein IT-Kollege David dagegen war schon immer recht datenabstinent. Ich glaube, er besitzt nicht mal einen Instagram-Account.
Tin, vielen Dank für das Interview!
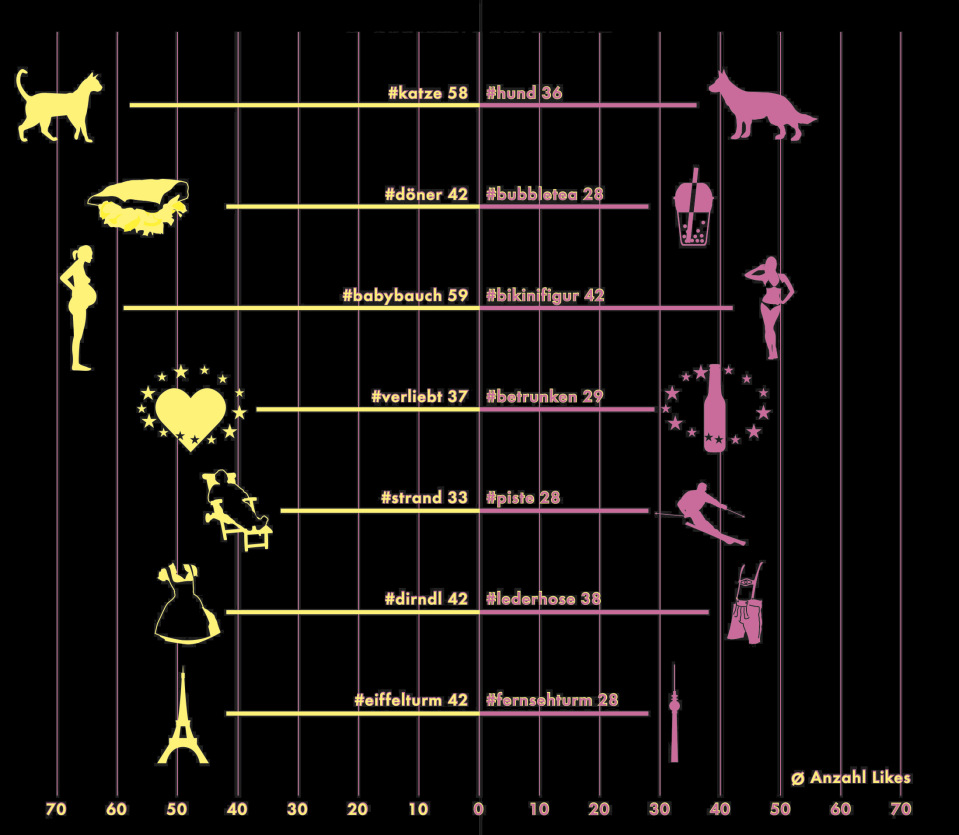
DAS HERZ IST DIE WÄHRUNG von Instagram. Natürlich bekommen Prominente, die viele Follower haben, mehr Likes als Normalnutzer. Aber auch das Motiv entscheidet über die Popularität eines Fotos. Eine Katze bekommt im Schnitt fast doppelt so viele wie ein Hund, der Babybauch ist beliebter als die Bikinifigur. Die Zahl der Likes ist übrigens so hoch, weil manche Nutzer Zehntausende Likes bekommen. (Daten: 2013+2014) – Quelle: Instarama
Data-Detox-Tipps

Jens Glutsch, Data Detox Berater
Der Diplom-Informatiker wird nun regelmäßig weitere Data-Detox-Tipps hier veröffentlichen. Der 42-Jährige hat in den vergangenen 15 Jahren als Software-Entwickler und IT-Consultant gearbeitet.
In diesem Jahr hat er sich als Berater für Data Detox, Privacy und Data Security selbständig gemacht.
Daten-Diät hilft beim Klarsehen

Ich fühlte mich vollkommen datenüberflutet. Von überallher ließ ich Daten auf mich einströmen: Nachrichten hier, Wetterberichte dort, eine Bewertung da nebst Kommentar. Ich verlor den Blick für das Wesentliche – nämlich mein Leben und deshalb habe ich beschlossen, eine Daten-Diät zu machen.
Im Selbstversuch habe ich sieben Tage lang konsequent keine Nachrichten oder Kommentare gelesen und keine Bewertungen mehr abgegeben. Ich merkte plötzlich, dass ich viel bewusster im Hier und Jetzt lebte.
Inzwischen suche ich gezielt nach Informationen, wenn ich zum Beispiel eine Reise plane oder eine Veranstaltung am kommenden Wochenende suche. So ist aus meiner Daten-Diät eine nachhaltige und gesunde Daten-Ernährung geworden, die ich seit meinem Selbstversuch beibehalten habe.
Datensparsam lebt sich’s gut

Meine Erfahrung mit Google hat mir gezeigt, dass es “da draußen” sehr viele Unternehmen gibt, die gerne an meine Daten rankommen möchten. Aber das will ich gar nicht, denn sobald meine Daten erst einmal “da draußen” sind, ist es unmöglich, sie wieder zurückzuholen. Daher frage ich mich inzwischen bei jedem Angebot, das ich im Internet nutze, sorgfältig, welche Daten ich dafür tatsächlich angeben muss. Natürlich will jeder Dienstanbieter möglichst viele Daten über mich sammeln, denn Daten sind im Internet die stärkste Währung.
Doch selbst wenn ein Eingabefeld als Pflichtfeld markiert ist, werden diese Daten in den wenigsten Fällen für die Erbringung der Dienstleistung benötigt. Ein Streaming-Dienst braucht deine Postanschrift einfach nicht, denn er liefert den Audio-Stream nicht per Post, sondern elektronisch. Wenn trotzdem ein Eintrag erwartet wird, na dann empfehle ich etwas Kreativität oder „Rächtschweibschreche“. Die wenigstens Formulare haben hier eine inhaltliche Prüfung (Privatsphäre sei Dank…).
Google muss nicht alles wissen

Google verdient sein Geld unter anderem mit dem Sammeln von Informationen über seine Nutzer. Schön und gut. Dummerweise erstellt Google dabei ein Profil von jedem User: Also was du suchst, wo du bist, wo du warst und gegebenenfalls auch, wo du hingehen willst. Diese Erkenntnis hat mich einigermaßen zornig gemacht, denn es geht Google absolut nichts an, was ich suche und wo ich war.
Um dieser Datenkrake nicht noch mehr Futter über mich zu liefern, verwende ich nun andere Suchmaschinen. Zum Beispiel startpage.com und DuckDuckGo, die mich nicht verfolgen und denen es vollkommen egal ist, wo ich war und wo ich hin will. Obendrein liefern beide sogar noch bessere Suchergebnisse als Google, wo deine Suchergebnisse als besonderer “Service” schon vorgefiltert werden. Schließlich weiß Google anhand deines Profils besser als du selbst, was du wirklich suchst und so ein bisschen Bevormundung ist doch ganz kommod…
Threema statt WhatsApp

Mit Begeisterung nutze ich digitale Kommunikationsmittel und plädiere in meiner Arbeit bestimmt nicht für die Rückkehr zu Steintafel und Brieftaube. Doch Instant Messenger wie WhatsApp – sorry, schlechter Stil, nicht das Negative wiederholen, sondernd das Positive verstärken.
Also nochmal: Instant Messenger wie Threema tragen unheimlich zu einer effektiven und schnellen Kommunikation bei. In unserer vom Marketing getriebenen Welt setzt sich nur leider oft das schlechtere System durch. So wie einst – die Älteren unter uns werden sich erinnern – bei VHS, womit nicht die Volkshochschule gemeint ist, sondern das elende Videosystem gegenüber Betamax.
WhatsApp bietet eine grotesk schlechte Sicherheit und doch verzeichnete es einen irrsinnig großen Kundenzulauf. Daher meine eindringliche Bitte an euch:
Steigt um von WhatsApp auf Threema und verbreitet euren Wechsel in eurer Peer-Group.
Threema bietet die gleiche Funktionalität wie WhatsApp, nur eben sicher.
Krypto ist cool und Menschen, die Krypto einsetzen, haben ein besseres Liebesleben und einen viel besseren Draht zu Gott. Den WhatsAppern bleibt dafür ein super guter Draht zur NSA.
Ich habe meine Webcam abgeklebt!

Klingt ein bisschen nach Alupyramide auf dem Kopf. Ist aber eine absolut einfache und vollkommen sichere Methode, unerwünschte Voyeure in meinem Laptop aus meinem Leben auszusperren. Außerdem erinnert mich der kleine Aufkleber stets daran, nie wieder zuzulassen, dass ich meine Privatsphäre leichtsinnig riskiere.
Mit dem Firefox / Chrome / IE Plugin „Ghostery“ kann man so einiges tun um seine Privatsphaere zu schuetzen. Man braucht noch nicht mal aus Facebook etc ausgeloggt zu sein.
Hallo Nick,
vielen Dank für deinen Kommentar. Du hast Recht Ghostery ist ein super Plug-in um sich vor Tracking zu schützen. Allerdings hat das grundsätzlich nichts mit den Metadaten von Fotos zu tun, die Apps wie Instagram über dich speichern könnten. Ghostery kommt dann in Spiel, wenn du über einen Internetbrowser auf Website gehst. Das plugin kann dich dann wie gesagt vor Tracking schützen, deine Daten bei Facebook zu preiszugeben verhindert es aber nicht.
Ich behalte das Thema im Hinterkopf, vielleicht wird das ja der nächste Detox Tipp.
Viele Grüße,
Jens
Zim Modifizieren bzw. Entfernen der EXIF Information __vor dem Hochladen__ soll ich einen Cloud Service benutzen, wo ich die Bilder hochladen muss ??? Das erschließt sich mir nicht. Woher soll ich wissen, was dieser Dienst mit meinen Originalbildern mit den ungeänderten Metadaten anstellt. Aber vielleicht bin ich auch zu paranoid
@Hans-Thomas Mueller:
Nutze entweder die Android- oder iOS-App, da lädst
du keine Daten hoch.
Ja, rein technisch betrachtet wird beim Hochladen einer Datei immer
eine Kopie auf dem Weg zu allen möglichen Servern, Routern, Switches, etc. abgelegt.
Aber da jetzt zu vermuten, die wollen die Bilder nur, um beim
Bearbeiten der Metadaten meine Metadaten abzugreifen…
…wow, das ist sogar mir zu verfolgungswahnsinnig…
Lieber Jens,
die Empfehlung von Threema durch scheinbar alle IT-Größen des Internets ist mir nach wie vor ein Rätsel. Denn Threema ist leider nicht open-source. Somit verspricht Threema mir: „Wir verschlüsseln deine Daten – ehrlich!“, im Unterschied zu WhatsApp: „Wir verschlüsseln deine Daten – ehrlich!“. Der Vorteil von Threema erscheint mir psychologisch – „die werden schon eine Verschlüsselung ohne Hintertür haben, immerhin gehören die nicht zu Facebook und sitzen in der Schweiz!“ Man vertraut lediglich einem anderem Unternehmen.
Ich würde TextSecure empfehlen, das – man muss es leider sagen – noch nicht den selben Komfort wie Threema oder WhatsApp besitzt, aber wenigstens von Server bis App allen Code offenlegt. Eine Hintertür ist auch hier nicht unmöglich, aber drastisch erschwert.
Ich bin gespannt auf deine Antwort!
LG Karl
Hallo Karl,


da sprichst du ein gutes Thema an: Muss eine Software, die verschlüsselte Kommunikation anbietet Open Source sein?
Nicht unbedingt.
Aber
Wenn die Software Open Source ist, kann durch die Community geprüft werden, wie gut die eingesetzte Verschlüsselung ist (und kann bei Fehler gegebenen Falls nachsteuern) und es kann sicher geprüft werden, dass hier keine Backdoor eingebaut ist.
Das sind beides Argumente, die deutlich für Open Source im kryptographischen Umfeld sprechen. Tatsächlich halte ich das auch für eines der wesentlichen Merkmale von kryptographischer Software, dass sie Open Source ist. Denn die Verschlüsselung über einen bekannten und offen implementierten Algorithmus durchzuführen stellt sicher, dass hier keine Backdoor vorhanden ist, um an die verschlüsselten Daten zu kommen.
Was jetzt Threema angeht hast du Recht damit, dass hier Closed Source eingesetzt wird und wir generell auf die Aussage von Threema vertrauen müssen.
Aber
Threema ist in der Schweiz ansässig und unterliegt dem Schweitzer Datenschutzgesetz. Das ist schon eine gute Sache. Und stellt deren Aussage schon in ein total anderes Licht als eine gleichlautende Aussage von WhatsApp (bei denen diese Aussage nicht die verwendeten Zeichen wert ist, die dafür eingesetzt wurden…).
Darüber hinaus wurde der Quellcode von Threema durch Reverse-Engineering auf seine Sicherheit hin geprüft (ähem…was zwar nicht erlaubt war…aber die Ergebnisse zeigten, dass hier keine Backdoor eingebaut ist und die Verschlüsselung wirklich gut ist 😉 ).
Was noch für Threema gegenüber TextSecure spricht ist, dass ein Threema-Account anonym betrieben werden kann.
Ja und was TextSecure / Signal (die Anwendung heißt seit kurzem jetzt Plattform-übergreifend Signal) angeht: Das ist tatsächlich durchgängig zu empfehlen, da es Open Source ist, starke Krypto bietet und auch Perfect Forward Secrecy (was bedeutet, dass selbst wenn ein Schlüssel, der einen Chat sichert gestohlen wird, nachfolgende Chats mit ihren eigenen Schlüsseln sicher sind).
Und was die Bedienbarkeit von Signal angeht: Ich glaube, diese wird sich in der Zukunft sicher der von Threema annähern
Ich danke dir für deinen prima Input und hoffe, dass ich deine Fragen beantworten konnte!
Herzliche Grüße,
Jens